
Preliminaries
In this post I brush over some basic NLP processes including text tokenisation, part of speech tagging as well named entity recognition. Particularly how these can be achieved in the Python Programming language through the Natural Language Toolkit (NLTK) package developed by Steven Bird and his associates.
NLP is broad field spanning Linguistics , Computer Science and Engineering, to mention a few. NLP which is used here to mean Natural Language Processing shouldn’t be confused with Neurolingistic Programming. NLP as we mean it here, is that field concerned with the interaction between machines and human languages, it seeks to make Language accessible to machines and to make human machine interaction much easier. This field is one which has come a long way, however there remains many NLP problems that are yet to be solved. The ultimate goal of the field may be considered to be true A.I (i.e a truly intelligent machine possessing every human cognitive ability, in this case the L.A.D and thus an ability to acquire, use, comprehend and learn Language).
NLP is at work everyday of our modern lives. Everything from search engines, to online translation services such as bing and Google translate, chatbots and text auto completion on our phones are NLP driven.
Basic Text Analysis with NLTK
What follows is a presentation of some very basic NLP procedures, with NLTK a NLP package for the Python Programming language, although not the only package available for NLP, it has the advantage of simplicity afforded by the nature for the Python Programming language(Other popular NLP packages include Stanford’s Core NLP, and Apache’s Open NLP, these packages are written in Java.). Amongst the numerous high level programming languages in existence, Python proves to be one of the least complicated, it is very true to the essence of such languages, as languages which are more human readable and portable than Assembler and Machine languages while sacrificing speed.




Tokenising Texts
- Word Tokenisation

- Sentence Tokenisation

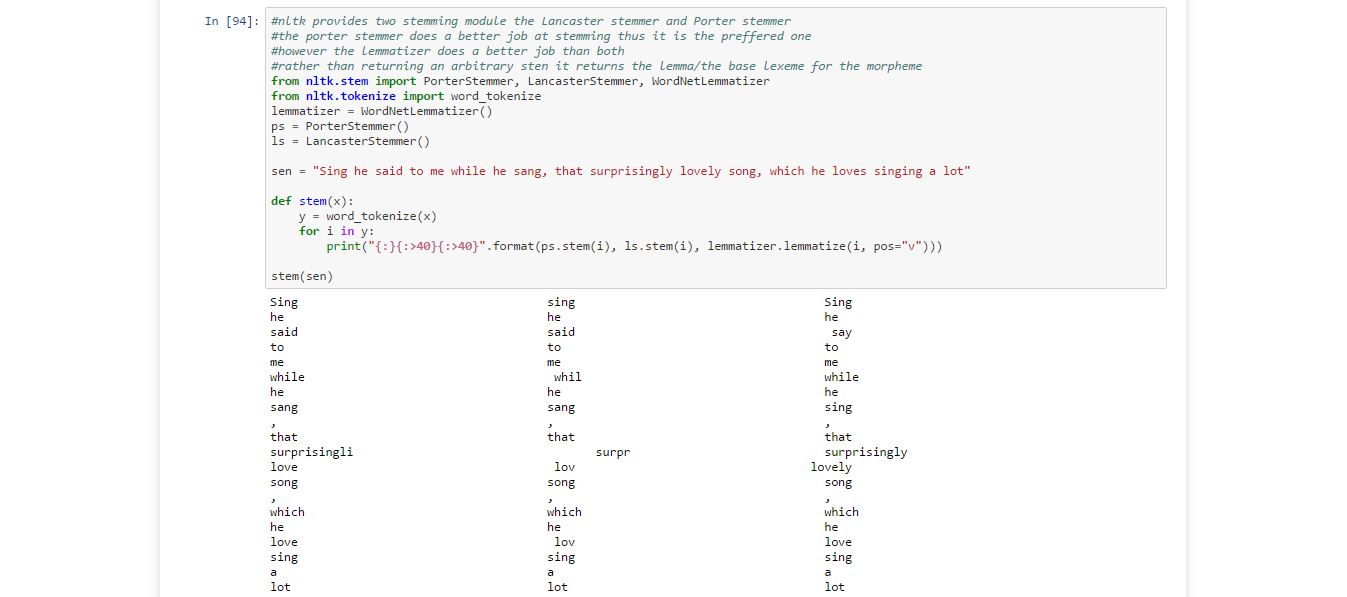
Stemming Tokens

Part of Speech tagging


Named Entity Recognition


The NLP functions presented are very basic.
What about more complex operations like relation extraction and explanation generation of deductive QA?
What are Python’s advantages over Prolog with which I know how to implement relation extraction and DQA with explanation quite simply.
John Kontos
AI professor
LikeLiked by 1 person
True the NLP functions discussed here are very basic. However the more advanced processes which you talk about can also be carried out in python, but I am not familiar with Prolog so I am not in a position to compare both.
LikeLike
I hope that you wouldn’t mind visiting http://www.nltk.org/book/ for more advanced discussions of NLP with nltk
LikeLike
I did look at the book at around p 400.
It is funny that the QA example refers to MY CITY !
We have translated factoid questions addressed to DBs from NL to SQL with Prolog many years ago.
The translation of NL to Logic is questioned by my work since 1992 on inference from text.
LikeLike
Please Can I get a copy of the work, I will love to study it.
LikeLike
You can find links and full texts of my pubs at : LinkedIn, Academia and Research Gate where I have posted a list of them too. If you find one listed that does not download please let me know and if I have it electronically I will send it ASAP to you.
All the best
John
LikeLike
Thank You
LikeLike